Author: Ben Moore
Read Time: 5 Minutes

Highlights at a Glance
- Benchmark Win: Outperformed Liquid AI’s foundation models with just 1B training tokens.
- Infinite Context: No fixed context window; can handle arbitrarily long sequences.
- Efficiency Breakthrough: Uses up to 40x less memory than equivalent transformers; runs locally on CPUs.
- Full Customization: Choice of OS, dependencies, and environment…critical for Quasar’s unique architecture.
- Early Belief: GPU Trader backed Quasar when other providers passed.
Breaking from the Transformer Mold
Quasar didn’t start out as a moonshot. Eyad Gomaa, CEO of SILX AI, originally planned to train another transformer model to compete with the major labs. But he quickly realized that was a losing game—transformers were already the incumbents’ territory, and challenging them on their own turf was costly and slow. Instead, Eyad began exploring liquid neural networks, a lesser-known architecture that’s adaptive rather than fixed. “To achieve the vision we wanted…what I call scientific intelligence…you need more than AI assistants or chatbots. You need something that can think in its own way and even decide how long to think before giving an answer,” he explains. Liquid neural networks offered part of the solution, but Quasar went further. Eyad’s team developed a way for the model to choose, in real time, whether to think longer or less depending on the problem — something no other lab had done.Finding a Partner Willing to Take the Risk
That kind of innovation can make people nervous. Before GPU Trader, SILX AI approached other compute providers, including Lambda, but found little appetite for a risky, unproven architecture. “They supported us a little, but they didn’t want to publish our story. They said our technology was still raw, and from talking to some of their employees, I understood they didn’t fully understand how it works.” When those talks fell through, Eyad reconnected with GPU Trader’s Matt Yantzer. “Thank you for believing in us and having this unique vision…taking a risk on something new and building the frontier.”Customization That Made the Difference
Eyad noticed the difference with GPU Trader immediately. Most platforms hand you a locked-down, pre-configured instance with their OS, their libraries, and their environment — and expect you to work within those constraints. GPU Trader took the opposite approach. “With GPU Trader, I could customize everything — the OS, the dependencies, even the notebook environment,” Eyad says. “For a custom architecture like Quasar, that was a huge advantage.” This flexibility wasn’t just a convenience. For Quasar’s non-transformer architecture, it was essential. The ability to configure environments from the ground up meant the team could fine-tune every aspect of their workflow. Even large-scale storage, often a bottleneck with other providers, was easier. “Even a single GPU could handle a lot of storage and workloads because you only rent what you need, not all the extra stuff that comes pre-installed with other providers.”Proving the Concept
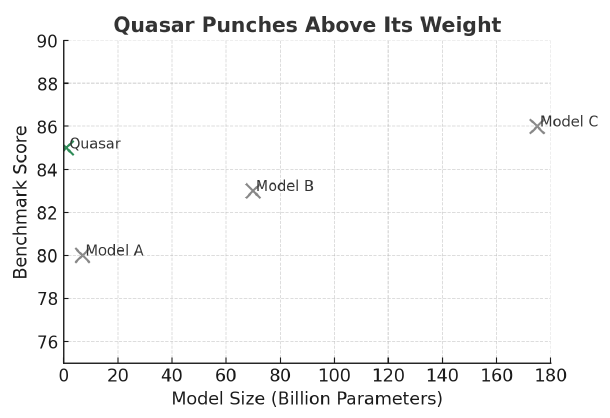
The results have been striking. Quasar outperformed Liquid AI’s own foundation models with just 1 billion training tokens — a fraction of the compute typically required to train a competitive LLM. The model also disproved the long-held belief that small models can only memorize. In testing, Quasar has matched or exceeded models 100 times larger. And because it avoids attention mechanisms entirely, Quasar has no fixed context window. It can handle arbitrarily long sequences, whether that’s an entire legal case file, a full software codebase, or massive research datasets. All without the limitations of today’s transformers. Performance Snapshot: